TextRNN
完整代码在github
TextCNN原始论文: Convolutional Neural Networks for Sentence Classification
TextCNN 的网络结构:
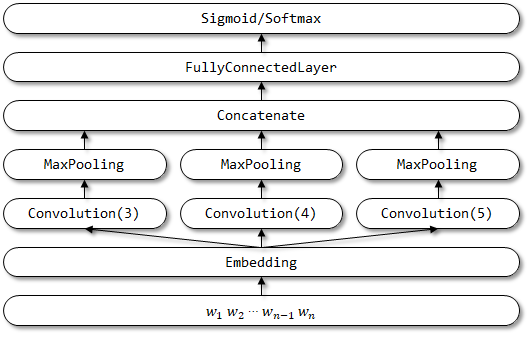
基于tensorflow2.0的keras实现
自定义model
这是tensorflow2.0推荐的写法,继承Model,使模型子类化
需要注意的几点:
- 如果需要使用到其他Layer结构或者Sequential结构,需要在init()函数里赋值
- 在model没有fit前,想调用summary函数时显示模型各层shape时,则需要自定义一个函数去build下模型,类似下面代码中的build_graph函数
- summary()显示shape顺序,是按照init()里layer赋值的顺序
1 | # -*- coding: utf-8 -*- |
main
构建模型helper,帮助构建模型,以及定义管理各种回调函数
- 其中主要回调函数有三个:EarlyStopping, TensorBoard, ModelCheckpoint
1 | # -*- coding: utf-8 -*- |