资源
完整代码+详细代码注释:github
原理
Transformer模型来自论文Attention Is All You Need。这个模型的应用场景是机器翻译,借助Self-Attention机制和Position Encoding可以替代传统Seq2Seq模型中的RNN结构。由于Transformer的优异表现,后续OpenAI GPT和BERT模型都使用了Transformer的Decoder部分。
Transformer算法流程:
输入:inputs, targets
举个例子:
inputs = ‘SOS 想象力 比 知识 更 重要 EOS’
targets = ‘SOS imagination is more important than knowledge EOS’
训练
训练时采用强制学习
inputs = ‘SOS 想象力 比 知识 更 重要 EOS’
targets = ‘SOS imagination is more important than knowledge’
目标(targets)被分成了 tar_inp 和 tar_real。tar_inp 作为输入传递到Decoder。tar_real 是位移了 1 的同一个输入:在 tar_inp 中的每个位置,tar_real 包含了应该被预测到的下一个标记(token)。
tar_inp = ‘SOS imagination is more important than knowledge’
tar_real = ‘imagination is more important than knowledge EOS’
即inputs经过Encoder编码后得到inputs的信息,targets开始输入SOS 向后Decoder翻译预测下一个词的概率,由于训练时采用强制学习,所以用真实值来预测下一个词。
预测输出
tar_pred = ‘imagination is more important than knowledge EOS’
当然这是希望预测最好的情况,即真实tar_real就是这样。实际训练时开始不会预测这么准确
损失:交叉熵损失
根据tar_pred和tar_real得到交叉熵损失
模型训练好后如何预测?
其中SOS为标志句子开始的标志符号,EOS为标志结束的符号
Encoder阶段:inputs = ‘SOS 想象力 比 知识 更 重要 EOS’
Decoder阶段:循环预测
输入一个[SOS, ],预测到下一个token为:imagination
输入[SOS, imagination], 预测下一个token为:is
…
输入[SOS, imagination is more important than knowledge]预测下一个EOS。最终结束
结束有两个条件,预测到EOS,或者最长的target_seq_len
网络结构
原始论文网络结构
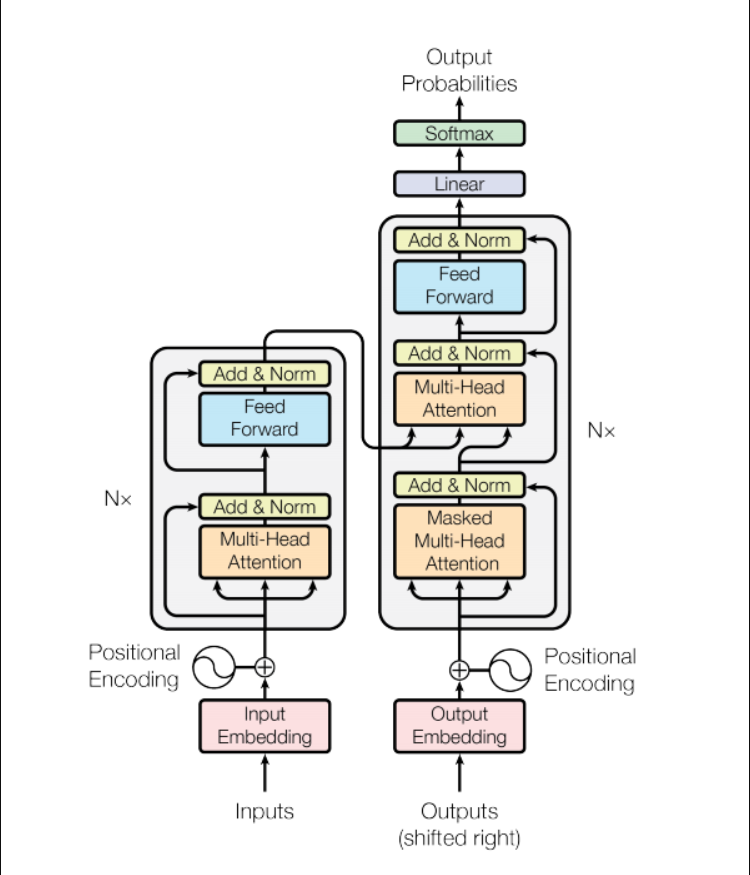
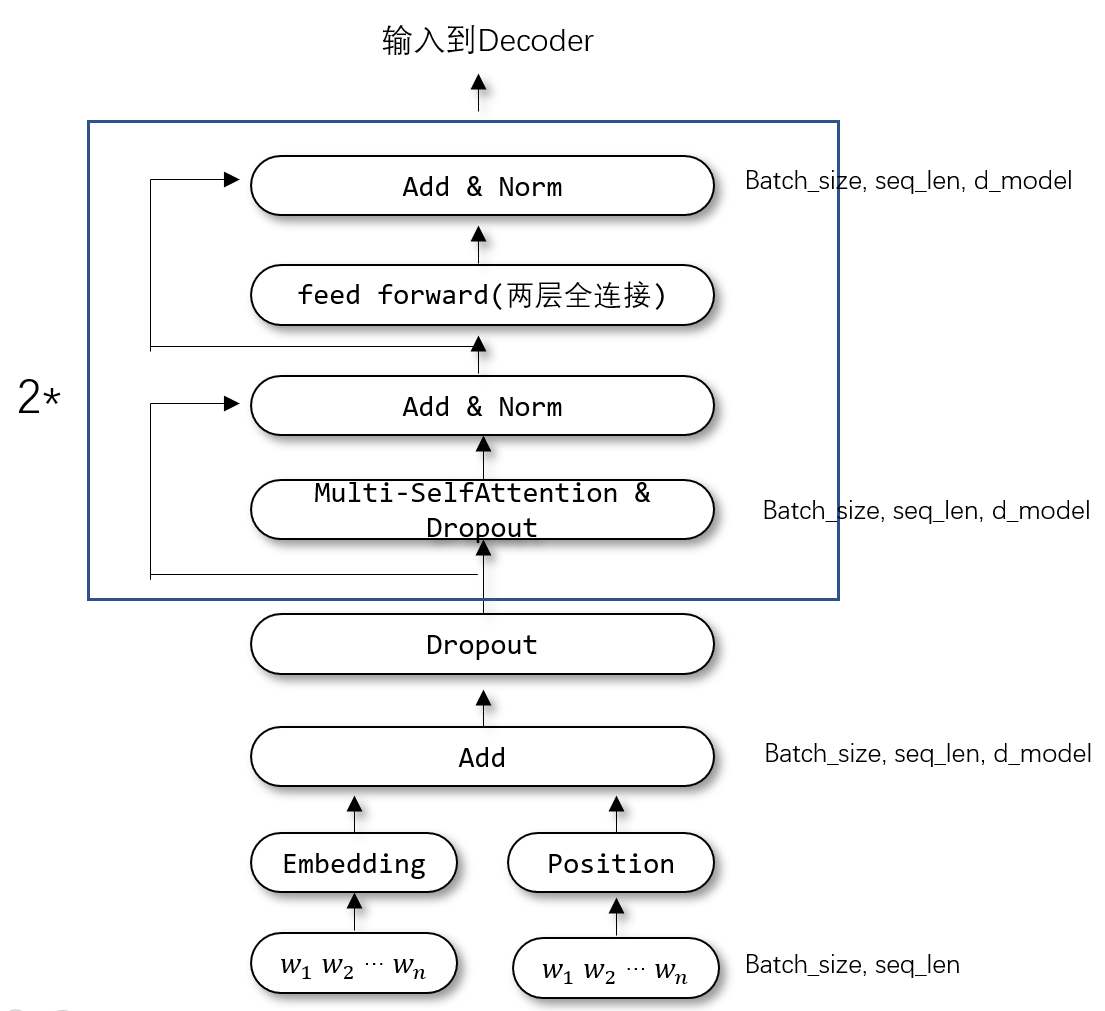
自己实现的网络结构:
Encoder部分:
下面伪代码中的解释:
MultiHeadAttention(v, k, q, mask)
Encoder block
包括两个子层:
- 多头注意力(有填充遮挡)
- 点式前馈网络(Point wise feed forward networks), 其实就是两层全连接
输入x为input_sentents, (batch_size, seq_len, d_model)
- out1 = BatchNormalization( x +(MultiHeadAttention(x, x, x)=>dropout))
- out2 = BatchNormalization( out1 + (ffn(out1) => dropout) )
Decoder部分:
和Encoder部分区别在于,Decoder部分先对自身做了Self-Attention后,在作为query,对Encoder的输出作为key和value,进行普通Attention后的结果,作为 feed forward的输入
Decoder block,需要的子层:
- 遮挡的多头注意力(前瞻遮挡和填充遮挡)
- 多头注意力(用填充遮挡)。V(数值)和 K(主键)接收编码器输出作为输入。Q(请求)接收遮挡的多头注意力子层的输出。
- 点式前馈网络
输入x为target_sentents, (batch_size, seq_len, d_model)
- out1 = BatchNormalization( x +(MultiHeadAttention(x, x, x)=>dropout))
- out2 = BatchNormalization( out1 +(MultiHeadAttention(enc_output, enc_output out1)=>dropout))
- out3 = BatchNormalization( out2 + (ffn(out2) => dropout) )
具体代码实现
Position
1 | def get_angles(pos, i, d_model): |
point_wise_feed_forward_network
1 | def point_wise_feed_forward_network(d_model, dff): |
Attention
其中MultiHeadAttention其实是在d_model(词embedding维度)进行split,然后做Attention
1 | def scaled_dot_product_attention(q, k, v, mask=None): |
Encoder
输入:
- inputs(batch_size, seq_len_inp, d_model)
- mask(batch_size, 1, 1, seq_len_inp),因为输入序列要填充到相同的长度,所以对填充的位置做self-attention时要做mask,这里之所以是(batch_size, 1, 1, d_model)的维度,是因为inputs做MultiHeadAttention会split成(batch_size, num_heads, seq_len_inp, d_model//num_heads),经过MultiHeadAttention计算的权重是(batch_size, num_heads, seq_len_inp, seq_len_inp ),这样做mask时,mask会自动传播成:(batch_size, num_heads, seq_len_inp, seq_len_inp )
输出:
- encode_output(batch_size, seq_len_inp, d_model)
1 | class EncoderLayer(tf.keras.layers.Layer): |
Decoder
输入:
- targets_inp(batch_size, seq_len_tar, d_model)
- encode_output(batch_size, seq_len_inp, d_model)
- self_mask(batch_size, 1, 1, seq_len_tar), enc_output_mask(batch_size, 1, 1, seq_len_inp)
输出:
- decode_output(batch_size, seq_len_tar, tar_vobsize)
1 | class DecoderLayer(tf.keras.layers.Layer): |
Transformer
1 | class Transformer(tf.keras.Model): |
Mask
1 | def create_padding_mask(seq): |
组合最终
1 | # ============================================================== |